游戏运维编年史可能是目前最详细的游戏运维指南
一直以来,中国网游在世界上都处于举足轻重的地位。从最早的端游到页游再到手游,不仅市场用户爆发式增长,近15年来网游技术的发展也是无比迅速。和单机游戏不同,网游除了游戏制作本身以外还牵涉到服务器端,再好的游戏如果出现链接、延迟等问题时也会造成巨大损失,这时候游戏运维便发挥了举足轻重的作用。中国网游的发展史,其实也是游戏运维的变革史,今天便由经典武侠手游《大掌门》运维掌门人吴启超来向我们讲述,进入游戏领域10余年来的风风雨雨。
如今我们说到游戏,可能想到的是火爆异常的VR,办公室里一言不合带上眼镜就地开打;亦或是刚刚虐了李世石的AlphaGo,扬言要挑战《星际争霸2》“教主”Flash。然而,除去这些还有一个游戏行业不可避免的潮流正在发生,那便是网络化。
这里说的不止是网游,前不久育碧旗下网游大作《全境封锁》上线时闹出个小笑话:由于很多国内玩家下载之前没注意是网游,下意识的以为育碧的游戏肯定是单机,好不容易下完之后才发现玩不上,进而发生了不少的骚动。这不是第一个发生这种情况的传统游戏厂商,肯定也不是最后一个,很多有名的游戏公司都在做类似的尝试,Popcap的《植物大战僵尸:花园战争》系列,暴雪的《暗黑3》等,甚至那些还有单机成分的大作也早就开始网络化:大名鼎鼎的《GTA5》、FPS风向标《使命召唤》系列和《战地》系列,网络联机部分的比重也在一年一年的增加。
网络联机,意味着玩家需要登录官方服务器,“有人的地方就有江湖”,这句话说的不仅是网游里的恩怨情仇,还包括游戏外的种种:“有服务器的地方就有运维。”这便是今天我们要说的话题游戏运维。
想要了解如今的游戏运维,不得不从早期的端游运维开始说起。对于08年入行端游,11年经历过页游最后14年全面接触手游的吴启超来说,这几年的游戏运维经历让他深切感受到运维思路的巨大转变。
1.1 端游的运维工种:IDC运维、系统型运维、网络运维、业务型运维、运维值班等。各个工种分工各有侧重。
业务运维:24点维护,零晨2点维护,零晨5点维护,早上7点维护
运维值班:0点盯着屏幕打电线点盯着屏幕打电线点盯着屏幕打电话
1.2 端游运维业务范围:在端游时代,大部分游戏公司都是自主做各种业务环境,做各种游戏业务需要的各种环境。
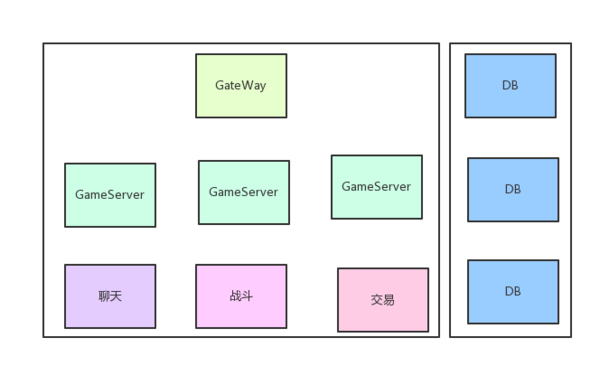
1.3 端游游戏服务器架构:一般来讲都是以一组服务器集群为一个区服单位,单机上的进程提供不同的服务。
传统运维,任务道远,正因为有过去那些年的翻译文档,兼顾整合方案,以及大批分享技术的前辈、社区,踩着前辈一步一个坑的走过来,才能有今天的运维的局面。
在2011-2013年左右的页游运维,游戏市场处于探索期,其实运维也处于探索期。端游时代每个新服都要经历上架、装系统,装服务的过程,一般一到两周可以上线一个区服,对于端游高粘性低流动的特性来说可能还好,但是当页游出现时,转变给运维带来的冲击无法估量。页游时代1天开100多个新服的概念,是传统端游运维所不能理解的。当时的运维认为页游就是把所有服务器实现自动部署服务,同时搭配运维自动部服工具就可以了。但事实上如果在开服时一组一组的使用物理服务器,开服速度根本跟不上,资源浪费还非常巨大,两周后用户留存率仅剩5%-7%。成本巨大亏空,急需技术转型,这个时间点上出现了两种概念影响了以后的手游以及云的发展。
在2010年11月份左右,kvm出现在RHEL6中,去掉了RHEL 5.X系列中集成的Xen。正是这一次虚拟化技术的转型,而且当时市场的需要,在2011年-2012年掀起了一场私有云建设的风潮。在实践过程中,优点很多,但暴露的缺点也不少。在端游占主要市场的情况下,实践过程中表现出来的不适尤其明显。
以上几点随着时间的推移有的已经然后解决,有的换上了代替方案。时至今日,端游在单纯的虚拟云上部署仍是问题,但是随着物理、虚掩混合云出现,这个局面应该可以被打破。
社区化的页游戏,为什么这样说呢,因为当时更多的页游信托社区入口,导入用户流量,当时最火的应该是人人网(校内网)的农场偷菜。然后是DZ论坛一堆农场插件袭卷全国,当然这一切都是为了增加用户粘稠度。但是也影响了页游技术的选型,当时基本上大家不约而的选用了于社区相同的LAMP的技术,从而降低开发成本及接入成本。当然现使用JAVA SSH2架构的页游也有。除技术选型外,同时还带入了另一个概念:联运。联运这个概念在页游时代对于端游运维就像一个恶梦,不同区服要随时跨服站,不同区服要随时可以合区,所有数据不再是以物理服务器为单位,而是要逐条打标签,再也看不到账号,只能拿着一串长长的KEY,四处兑换,然后拿着不知道所谓的表标问第三方.
在这个时期,是运维开发的爆发年,随着虚拟化技术的推广,越来的越多的运维开始接触自动化运维的概念,开始了自动化运维的奋斗之路,开始了以项目管理的角度看待运维脚本开发。
随着私有云转为公有云、云时代推动着云计算以及移动互联网的发展,网游行业慢慢进入了手游黄金时代,云时代的变革不仅挑战了整个游戏行业,也挑战了游戏运维。
3.3 手游游戏服务器架构:一般来讲都是以一组服务器集群为一个平台单位,不同的集群提供不同的服务。

手游的架构理念是提供一组虚拟服务器,当短连接的时候,每开一组服,将玩家引导到Web集群,随后被分配到不同的MongoDB,数据缓存用在Redis。当第一个服务器玩家请求DB时,会落到Mongo1上;当开第二个服的时候,还是将玩家引导到Mongo1上;以此类推直到运维发现压力累积到一定程度时,便会新开一组MongoDB,Web集群也是如此但只有性能不够时才会添加,一般情况下,每50个新服可能需要添加1个MongoDB。这便实现并解释了当时在页游里希望实现的快速开服方法。
到此为止我们已经回顾了一遍游戏运维从端游到页游再到手游的演变过程,不难看出,手游对于区服的架构概念不同于端游:端游认为一个物理集群是一个服,而手游认为一个Web请求落到相应的数据库上就是一个服。这样的好处是开服合服都简单,如果前五十组服务器需要合并,实现起来很容易,因为同一个DB的数据是互通的,所以只需发一个公告,服务器加标识即可,不需要进行物理操作也不需要数据迁移。
说完了游戏运维的历史,我们要开始今天的重头戏,如何做好游戏运维?这里就用吴启超的一个冷笑话作为开始:运维为什么存在?a,有服务器;b,因为研发忙不过来。不管是笑没笑,运维确实因为上面两个原因才会诞生的。那么回到正题,想成为玩转上千服务器的游戏运维应该怎么样做呢?系统部运维构建大致如下图:
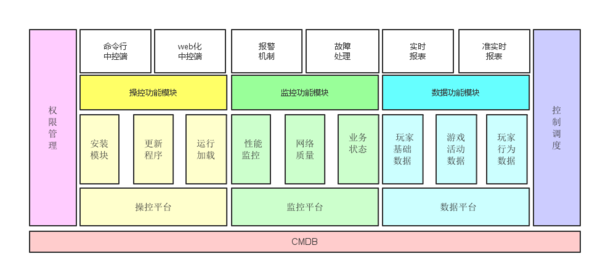
21世纪什么最重要?信息最重要!运维所需信息要涉及:机房、物理服务器、虚拟机、交换机、网络、承载业务、业务配置、承载服务进程、端口等信息。不管是自己采购还是购买云服务,物理服务器和虚拟服务器都做为资产存在,在采购后录入相关的资产管理,给它打上标签,属于哪个游戏,哪个平台,这样不同游戏平台间就不能混用服务器了。然后,是再给不同的服务器标识它承担的业务角色,比如它是MongoDB,我们需要打上的标签会是大掌门-APPSTORE-MongoDB-主库-90000端口-第一组服务。这样一个基础信息录入就完成了。
这样的信息只要是用来将来批量化部署、管理服务器使用,以及当出现故障时,运维可以很方便的查询相当的服务器以及服务信息。但是数据的及时性、准确性、可检查是一个难点。
CMDB不是TXT文件,而是要变成EXE文件。运维在面临大量服务器的情况下,批量化工具的出现成为必须的结果,在日常的工作当中需要把其流程固化下来,为完成批量化安装、管理打下基础。大掌门喜欢使用ssh sshpass paramiko libssh2这些基础的技术做批量管理。原因是不用安装简单、稳定、安全、可控。当然吴启超也表示推荐大家使用在市面上流程行puppet、Ansible、SaltStack等技术,为什么?简单、简单、简单!下图就是在做自动化半自动化运维过程中的模型。
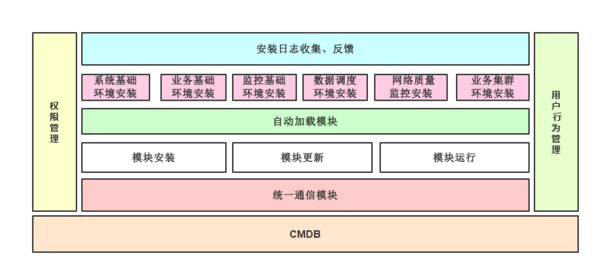
1、每天都会对服务器进行上线,升级等操作,每款游戏在一个平台的集群数在几十个到几百个不等(根据平台大小)。因此每天维护和升级服务器压力极大,服务器异常或响应慢等问题的发生会给用户体验带来伤害。这样的隐患在于一旦发生游戏关服之后就必须对玩家进行游戏中货币和元宝的赔偿,平均每个玩家补偿的元宝至少在5元以上,游戏币和各类游戏道具若干,以此类推由于服务器故障造成的损失可想而知。
2、大掌门使用了听云Server,能够对服务器响应慢和不可用进行定位,查看慢应用追踪和Web应用过程功能,能够实时定位消耗资源最大的代码和语句,这样就能帮助实时进行有针对性的调整和优化,并且可以快速定位问题时间,最快能到分钟级别。

3、发生高并发、服务器压力激增的情况时,平时运行正常的服务器异常概率大幅增加,日常可能的性能瓶颈点会被成倍放大,这就需要实时定位和解决性能瓶颈点,和提前进行预防改善。一般来说,传统日志收集方式耗时耗力,效果非常不好,大掌门用了听云Server后,可以进行1分钟级定位能迅速有效发现瓶颈点。同时还结合了听云Network的压测功能,能够在服务器上线前提前发现到高压力下的瓶颈点,提前预防,避免由于高并发出现的服务器瓶颈
4、还有一种性能情况需要提前预防,游戏公司盈利在于玩家的充值,对于官网上从登陆到充值全流程的成功率业务部门极其关注,玩家点击跳转的失败会直接导致充值付费用户的转化率。对此,大掌门通过听云Network的事务流程功能能够实时对事物流程进行警报,帮助业务部门提升用户充值的转化率
对此,大掌门开发了一套适用于全公司所有的游戏的统一登陆、充值、交易平台,解决了前端的SDK接入的问题,一个所有游戏或第三方的API接口统一接入的平台。在做业务型监控时,运维会要求后端开发人员写一个特定账号,在访问现有系统时,会完整的走一遍业务流,这样就可以看到需要的业务数字。

上图为大掌门数据仓库的结构图,由于数据仓库搭建的话题比较大,只是简单的从数据集市的角度来聊聊,DM指的是数据集市。由于数据集市需要面对不同的人群,因此在数据仓库中需要建立不同的数据集市以面对各方的查询需求,进而对数据按照业务类型进行分类。
对于数据方面,运维的压力来自于需要贯穿及掌握所有的数据,并且为所有部门服务。简单的以下图的ETL为例:

1、将数据日志进行切割(按照业务打包日志)并合理命名。比如A登陆日志,B充值日志,C消费日志。分门别类进行打包后,对数据每5分钟切割1次,并生成md5包。
2、按照划分IDC Region。原来从本机向外传输数据会占用大量带宽,对于本身CPU的消耗大的话都会影响游戏的运行。现在按照IDCregion做出划分,每个区域中会有1-3个中心存储服务器。将切割下来的数据放到中心存储上,划分成Aip1、Aip2、Aip3等md5压缩包,此处无需做合并(原因见3)。
3、建立下载任务。建立好任务列表后,对每5分钟的压缩包进行下载。考虑到如果上面的步骤做了合并的话就可能会产生在传输的时候丢数据却无法确定的情况,因此2步骤无需对数据进行合并。
4、将下载后的任务加到Hive数据仓库里。将当天的数据放到MySQL中,之前的数据放到Hive里。当运营提出数据需求时便可以到Hive中下载数据。即使数据出现错误,按照上面建立的每5分钟的任务列表也可以重新以规定时间点将数据压缩包重新拉回来。并且该流程可以按照正向、反向双向进行。
采用5分钟压缩包的另外一个原因在于每台服务器每天产生业务日志大概有5-6G的数据,分到5分钟后,切割完每个文件就是20M-30M,压缩后只占用很少的空间。这样就解决了占用大量带宽的问题。
5、数据传输后需将数据放到数据仓库(DW)中,数据下载完毕后会根据文件进行存储,当天的数据按照5分钟1个压缩包进入MySQL,MySQL则进入当天的查询。在数据仓库中,数据包按游戏及平台进行分类,这种格局的安排为了在并发时更好的运行。由于游戏与游戏之间是隔离的,因此按照这种模式是为了保证数据进行顺利并发。